Real2Sim & Sim2Real — Genesis-based Physical Learning
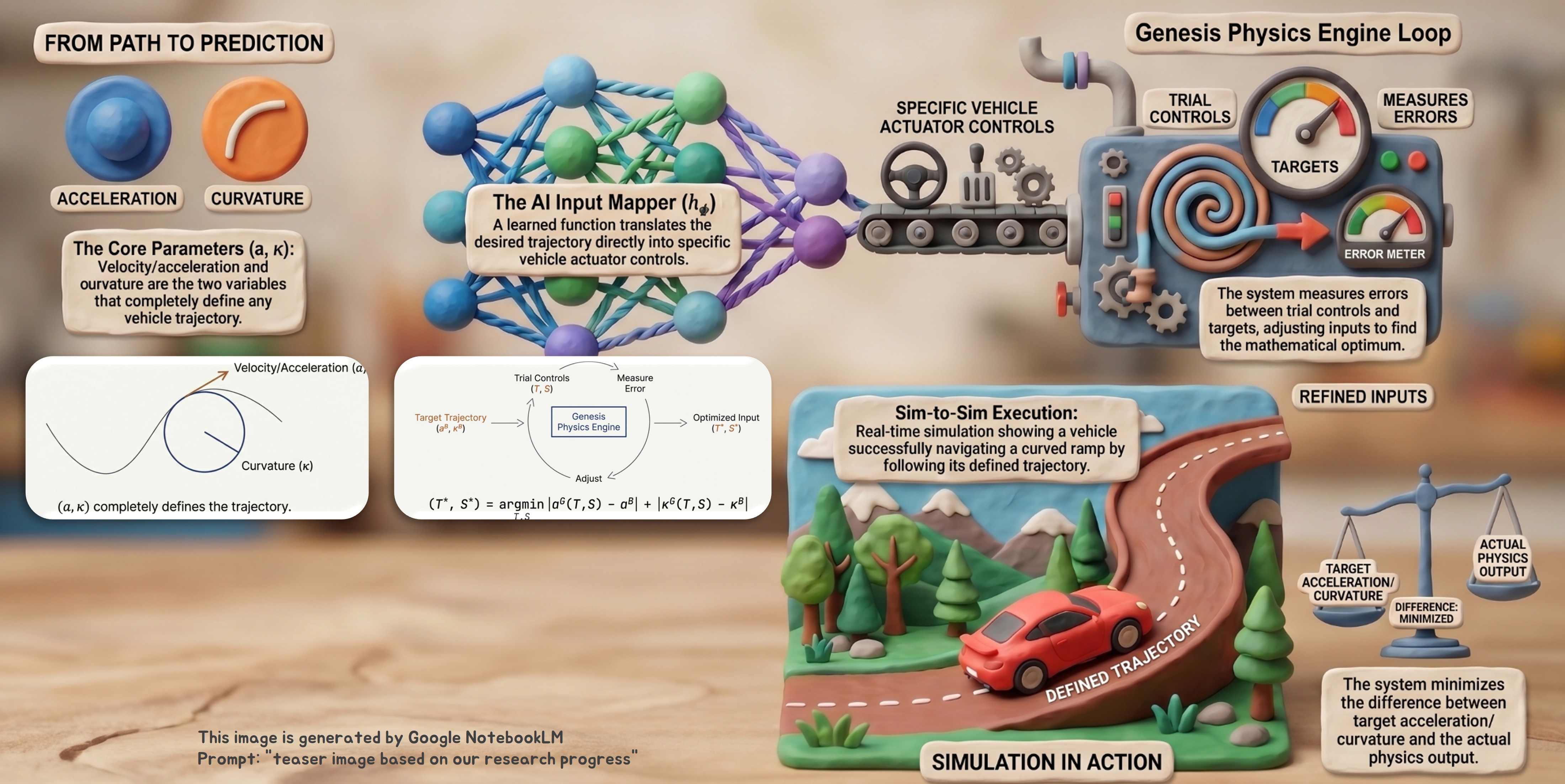
We develop a unified Real2Sim / Sim2Real pipeline built on the Genesis physics engine. At its core are neural inverse-dynamics and trajectory-to-controls (ST, B) mappers that recover control inputs and dynamics-correction terms directly from observed real-world rollouts — providing the calibrated bridge that supports residual learning, multi-agent training, and robust deployment on the physical platform. Our long-term goal is a closed-loop framework where (i) real-world rollouts continuously calibrate the simulator and recover the latent control trajectory, and (ii) policies trained in the calibrated sim transfer back to the real platform with quantifiable robustness.
Recent directions include:
- Inverse-Dynamics & Trajectory-to-Controls (ST, B) Mappers: The core of our calibration stack. Given an observed trajectory, lightweight neural mappers recover (a) the underlying control inputs — steering (ST) and brake (B) — and (b) the inverse-dynamics function aligning Genesis to real-world rollouts. This explicit recovery of control + dynamics closes the sim-to-real gap before any policy learning starts and is the common substrate that the rest of the pipeline (residual RL, neural physics, multi-agent training) builds on.
- Residual Learning across Supervised + RL: A behavior-cloned base policy is augmented by a residual reinforcement-learning head that compensates for covariate shift and unmodeled dynamics, achieving sub-millimeter trajectory drift on Genesis solver-optimized environments.
- Large-scale Multi-Agent Combat Simulation: 3v3 tank-warfare environment with curriculum-based multi-agent reinforcement learning, scaling to thousands of parallel simulated worlds and credit-assignment designs that survive sparse rewards.
- Neural Physics: Learned correction terms that augment classical simulators where calibration alone is insufficient (terrain, contact, suspension dynamics).
programming experience
Python, PyTorch, Genesis, Isaac Lab, Blender, RL frameworks (PPO/QMIX), behavior cloning + residual RL pipelines