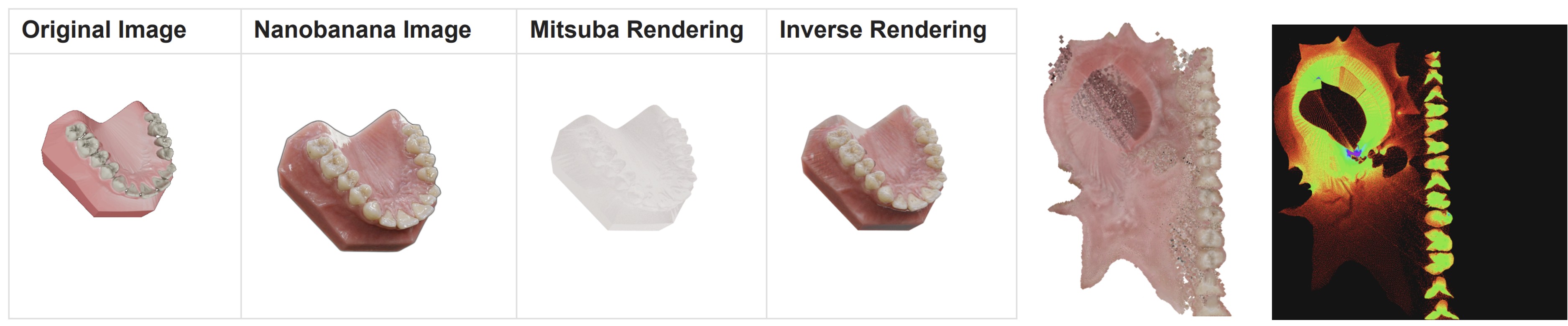
Dental Realistic Inverse Graphics
We turn a single-material 3D mesh equipped with semantic part labels (enamel, gum, dentin, per-tooth IDs) into a full pipeline for photorealistic dental image synthesis, open-model distillation, and large-scale segmentation data generation — while remaining tightly coupled to our existing dental inverse-graphics and realistic visualization stack (DiT priors, 3D Gaussian Splatting, differentiable physically-based rendering).
Recent directions include:
- Semantic-Mesh-Driven Photorealistic Synthesis — Teacher-Anchored Hybrid Pipeline: Given a single-material mesh with semantic regions, we generate the anchor view with a strong proprietary diffusion teacher (Gemini-class), exploiting its semantic-aware zero-context generation. The anchor texture is baked back onto the mesh via sampling-aware multi-view baking (gathering + z-buffer + cliff masks), and remaining views are completed by an open-source multi-ControlNet (semantic + depth + hole-mask) inpainting stack on the residual holes only. The proprietary footprint is reduced to a single anchor view per mesh.
- Open-Model Distillation from a Proprietary Teacher: We treat Gemini-class models as a black-box teacher and distill their high-fidelity, semantic-aware appearance into an open-source SDXL + multi-ControlNet inpainting stack. The mesh-aware anchor texture serves as an image-level distillation target that conditions the open model so it only has to fill small, context-rich residual holes — the regime in which open-source inpainting is strongest. The result is an end-to-end open pipeline whose quality is anchored, but no longer bottlenecked, by a single proprietary call.
- Tooth Segmentation Data Pipeline — Synthetic Supervision at Scale: Because the underlying mesh carries semantic part labels, every rendered view automatically comes paired with perfect ground-truth segmentation masks (per-tooth, gum, occlusal surface). The teacher-anchored renderer becomes a synthetic dataset generator that emits thousands of (photorealistic image, exact mask) pairs across varied viewpoints, illumination, and material parameters, directly feeding downstream tooth segmentation, detection, and instance models.
- Plug-in to Dental Realistic Visualization and Inverse Graphics: The same multi-view texture / material stack composes with our existing photorealistic dental visualization and inverse-graphics solvers — DiT-driven priors, Mitsuba3-based differentiable rendering, 3DGS proxies for expensive path-tracing kernels, and wild NeRF / 3DGS alignment with explicit visibility terms. The synthetic data pipeline and the real-data inverse pipeline share representations and downstream consumers, so improvements on either side propagate to the other.
programming experience
Python, PyTorch, Diffusers (SDXL + multi-ControlNet inpainting), Gemini API, Mitsuba3 differentiable rendering, 3D Gaussian Splatting frameworks, semantic-mesh texture baking (xatlas, z-buffer, cliff masks), perfect-GT synthetic data pipelines